The August 2010 issue of CACM published an article by Gary Anthens on Mechanism Design Meets Computer Science.
Archive for July, 2010
CACM article on Mechanism Design and CS
Posted in Uncategorized on July 29, 2010| Leave a Comment »
Yu Jiajin reports on Shanghai AGT Summer School
Posted in Uncategorized on July 28, 2010| 1 Comment »
Yu Jaijin reports on the GAME 2010 summer school in AGT that was held in Shangai early this month:
The theory group at Fudan University hosted a Summer School on Algorithmic Game Theory (GAME 2010) in Shanghai from July 4th to July 15th. This was a greatly successful event that attracted more than sixty participants from China, Europe, other Asian countries, and the US. Most of them were students, but some postdocs and researchers attended as well. Nine invited speakers gave great lectures about various aspects of algorithmic game theory, and several participants presented their own research results. In addition to the enlightening lectures, the school organized an exciting excursion to EXPO 2010 and a nice banquet in a gorgeous Chinese garden restaurant. The complete schedule can be found at http://www.tcs.fudan.edu.cn/game10/program.html.
The following topics were covered in the summer school:
- Avrim Blum and Rudolf Fleischer started the summer school with an introduction into game theory and mechanism design, introducing the main concepts and giving some first examples of games and mechanisms.
- Andrei Border talked about the fascinating world of computational advertising by presenting some of its key features and comparing it to traditional advertising. His presentation included many vivid examples and figures from real world applications (like retrieving good ads in the sponsored search auction and the guaranteed delivery of display ads), and various kinds of research behind it (IR, optimization, etc.).
- Stefano Leonardi’s lectures were mostly related to the design of approximation algorithms for truthful mechanisms (like cost sharing mechanism). He taught how to adapt classic approximation algorithms to truthful ones in the utilitarian mechanism design, and presented his recent work about Pareto-optimal combinatorial auctions whose motivation came from Google TV ads.
- Kamal Jain first talked about Internet Economics. He believed search engines collected intentions from users and sold them to advertisers, which were on an atomic scale, while in traditional advertising aggregate interests are sold. He then presented two of his interesting recent research results. The first one was how to decide the existence of a matching in some lopsided bipartite graph, coming from the context of matching targets for display ads. The other one was about market equilibria in a market where agents are both consumers and producers of the content that belongs to one of several categories.
- Maria Florina Balcan talked about fundamental connections between learning theory and game theory. She first gave a tutorial about online learning and regret minimization and taught the Weighted Majority Algorithm and its randomized version (RWM). She then showed a simple proof of the famous Minmax Theorem in zero-sum games based on guarantees of the RWM algorithm. She also talked about games with many players games with interesting structure, namely about potential games. In addition to presenting basic properties of such games, she talked about some recent research about leading dynamics to good behavior in games with a huge gap between the quality of the best and the worst Nash equilibrium. For example she showed that in cost sharing games if only a small fraction number of the agents followed the good advice proposed by a central authority, then within polynomialnumber of steps the game will converge to a state with good social welfare. Finally, she also presented recent work about learning submodular functions in a setting similar to the traditional PAC model.
- Avrim Blum gave lectures about game theory, mechanism design, machine learning, and pricing problems. He first introduced the concept of internal/swap regret and showed that if players use no internal-regret strategies, the empirical distribution of the game will be a correlated equilibrium. He then talked about two interesting applications of machine learning techniques for designing incentive compatible mechanisms for revenue maximization in unlimited supply settings. The first one concerned the online digital good auction: how to adapt pricing for a single digital good to achieve performance matching the best fixed price in hindsight. He also showed how to use ideas from machine learning to convert batch optimization algorithms into incentive-compatible mechanisms with performance close to the best pricing function in some class of pricing functions. Finally, we also talked about about some interesting algorithmic pricing problems in this setting as well.
- Eva Tardos’s lectures were mostly related to the price of anarchy. She first gave a very gentle introduction of congestion games in atomic and non-atomic settings. Then she taught a technique called (λ, μ) – smoothness that can prove stronger bounds of PoA for non-atomic games. She also presented the work about some multiplicative update learning process that will converge to a weakly Nash equilibrium in polynomial time. At last she talked about a recent work of PoA in GSP auction. Using some combinatorial structures in the auction, they could show a constant bound of PoA of pure Nash, mixed Nash, and Bayesian-Nash in GSP auctions.
- Xiaotie Deng gave a proof sketch of the celebrated result concerning the PPAD-completeness of finding mixed Nash equilibria in 2-player game. After introducing the PPAD class, he showed the reduction in the following way: 2D Another End of Lines => 2D Sperner Problem => 2D Discrete Fixed Point Problem => 2-player Nash Equilibrium Problem.
- Ning Chen covered several important known results on stable matchings and its Pareto-optimal extensions, including the GS algorithm, the Roth-Vande Vate Algorithm that solved Knuth’s local search problem, and some extensions like having partial orders or ties in the preference lists. Ning Chen and Xiaotie Deng then presented together their recent work about market equilibria in the advertising business. They gave a polynomial time algorithm that found the minimum market equilibrium price where agents had budget constraints.
Reputation for Human Computation
Posted in Uncategorized on July 28, 2010| 7 Comments »
Like many, I am fascinated by the notion of “Human Computation“: algorithms that use black-boxes that are implemented by actual humans. The fascination is probably mostly due to the “inverse” interface between humans and machines: what we are used to is humans using black-boxes that are implemented by computers; now the roles are switched. Add to this the unexpected effectiveness of this practice and one can certainly start musing about practical possibilities, various philosophical-leaning directions, as well as actual research questions.
Amazon’s Mechanical Turk brings this possibility into the hands of many, and in particular I have been hearing more and more researchers who are attempting to use it for running experiments on human subjects. Many questions regrading the validity, ethics, and administration of such experiments suggest themselves, and these questions are starting to be addressed.
I have been following with interest Panos Ipeirotis’s stream of blog posts about the Mechanical Turk , the last of which suggests that the lack of a sufficient reputation mechanism is leading to the failure of the Mechanical Turk labor market. In other words, “spammers” abound and are hurting the proper functioning of the market. Building a sufficiently good reputation mechanism would seem to require the proper blend of dealing with the humans and the computers, a blend that may be especially interesting due to the “inverse” roles of humans and machines in this setting.
AGT Workshop in Tehran
Posted in Uncategorized on July 27, 2010| 1 Comment »
On July 29, 2010, there will be an AGT workshop in Tehran.
Online Dating
Posted in Uncategorized on July 25, 2010| 4 Comments »
Hat tip to Al Roth for pointing out an interesting clip of Dan Ariely talking about online dating.
The world of online dating is one of the most significant demonstrations of how much the Internet has changed our lives. Finding a spouse (or even just sex) is one of the most basic human activities and every culture has put much effort into structuring it just so. Yet, within a very short time, online dating has captured a huge share of this deeply socially rooted “market”. I would say that this is more due to the deficiencies of the current “offline” models than due to the strength of the current online systems. Maybe it is time for some new models of online dating?
IPAM workshop on AGT
Posted in Uncategorized, tagged Conferences on July 17, 2010| 2 Comments »
The institute of Pure and Applied Math (IPAM) at UCLA is having a workshop on Algorithmic Game Theory on January 10-14, 2011 with an impressive list of confirmed speakers. Registration by November 15th is recommended.
Regret in Markets
Posted in Uncategorized, tagged complexity of equilibria, technical on July 13, 2010| 3 Comments »
How do markets and other games reach equilibrium? Or at least, how can they do so? A nice answer will have each participant in the market or game repeatedly performing some simple update step that only depends on information available to him and that makes sense from his local point of view, with the whole system then magically converging to equilibrium. The meanings of “simple”, “update”, “information available”, “makes sense”, and “converging” may vary, but the idea is to capture the basic phenomena of a global equilibrium arising from simple local optimizations.
In this post I will describe some recent work that shows this kind of phenomena where local “regret-minimization” optimizations lead to global convergence in a natural market model.
Regret and Online Convex Optimization
We start by looking at an online optimization strategy for a single decision maker that interacts with an adversarial environment. It will be nicest to use the general and clean model of online convex optimization due to Zinkevich. This model considers an sequence of functions 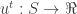


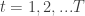


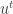

Definition: A sequence of points 

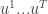
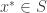
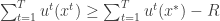
The main point is that there exist online algorithms that always find such low-regret sequences when 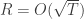
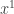


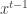


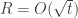


Coarse Equilibria in Games
So far we were in a decision theoretic model of a single decision maker. Now, what happens when several different decision makers are using such a regret-minimization procedure together? Formally, we have an 





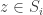
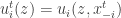
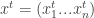
Definition: Let 
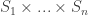

![E_{x \sim D} [u_i(x)] \ge E_{x_{-i} \sim D_{-i}} [u_i(x^*_i,x_{-i})]](https://s0.wp.com/latex.php?latex=E_%7Bx+%5Csim+D%7D+%5Bu_i%28x%29%5D+%5Cge+E_%7Bx_%7B-i%7D+%5Csim+D_%7B-i%7D%7D+%5Bu_i%28x%5E%2A_i%2Cx_%7B-i%7D%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)


![E_{x \sim D} [u_i(x)] \ge E_{x_{-i} \sim D_{-i}} [u_i(x^*_i,x_{-i})] - \epsilon](https://s0.wp.com/latex.php?latex=E_%7Bx+%5Csim+D%7D+%5Bu_i%28x%29%5D+%5Cge+E_%7Bx_%7B-i%7D+%5Csim+D_%7B-i%7D%7D+%5Bu_i%28x%5E%2A_i%2Cx_%7B-i%7D%29%5D+-+%5Cepsilon&bg=ffffff&fg=333333&s=0&c=20201002)
Intuitively, we can think about a trusted coordinator who picks a profile of strategies 
Proposition: If all players have regret 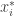
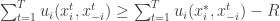


Let us just look what this implies for finite games in which players have a finite set of pure strategies. To apply the results form online concave optimization, the regret algorithms will be run over the set of mixed strategies, which is a compact convex set. In this case the utility for a profile of mixed strategies is the expected utility of the chosen pure strategy profile. Thus once 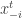
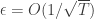

Socially Concave Games
Just the fact that we have called what is reached (in the sense of average over time) an equilibrium does not mean that we have to like it from a game theoretic sense. Could we get a “normal” equilibrium from such corse equilibrium? Even-Dar, Mansour, and Nadav point out a family of games, termed socially concave games, where this is the case.
Definition: An
- For each
is convex in
.
- The sum
is a concave function of
.
Theorem: Let ![\hat{x} = E_{x \sim D} [x]](https://s0.wp.com/latex.php?latex=%5Chat%7Bx%7D+%3D+E_%7Bx+%5Csim+D%7D+%5Bx%5D&bg=ffffff&fg=333333&s=0&c=20201002)
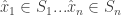
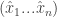
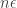
This theorem ensures a pure equilibrium in the game with convex strategy sets. Looking at the case that the game is the mixed extension of a finite game, this is translated to a mixed equilibrium of the finite game. Before we prove the theorem let’s look at a simple application: two-player zero-sum finite games. Looking at the mixed extension we have 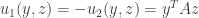



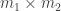


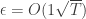
Proof: We will prove the exact version, the quantative is identical, only taking care of the 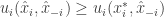

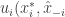
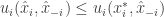
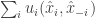
![\hat{x} = E[ x]](https://s0.wp.com/latex.php?latex=%5Chat%7Bx%7D+%3D+E%5B+x%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\sum_i u_i(\hat{x}_i,\hat{x}_{-i}) \ge E[\sum_i u_i(x_i, x_{-i})]=\sum_i E[u_i(x_i, x_{-i})]](https://s0.wp.com/latex.php?latex=%5Csum_i+u_i%28%5Chat%7Bx%7D_i%2C%5Chat%7Bx%7D_%7B-i%7D%29+%5Cge+E%5B%5Csum_i+u_i%28x_i%2C+x_%7B-i%7D%29%5D%3D%5Csum_i+E%5Bu_i%28x_i%2C+x_%7B-i%7D%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![E[u_i(x_i, x_{-i})] \ge E[u_i(x^*_i,x_{-i})]](https://s0.wp.com/latex.php?latex=E%5Bu_i%28x_i%2C+x_%7B-i%7D%29%5D+%5Cge+E%5Bu_i%28x%5E%2A_i%2Cx_%7B-i%7D%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)

![E[u_i(x^*_i,x_{-i})] \ge u_i(x^*_i,\hat{x}_{-i})](https://s0.wp.com/latex.php?latex=E%5Bu_i%28x%5E%2A_i%2Cx_%7B-i%7D%29%5D+%5Cge+u_i%28x%5E%2A_i%2C%5Chat%7Bx%7D_%7B-i%7D%29&bg=ffffff&fg=333333&s=0&c=20201002)
A Market Equilibrium
We can now take this general result and apply it to a rather general market model. This is due to Sergiu Hart and Andreu Mas-Colell. (When I asked Sergiu how should I refer to this result, he said something like “had we been computer scientists this would have already been published in a conference; since we are economists these are preliminary thoughts that maybe will find their way into a paper within a few years”.)
Our market has 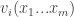
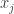

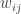

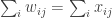
Definition: The allocation 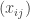
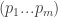

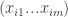
We now turn this market into a game. For this, we will require the minor technical assumption that the partial derivatives of the 

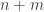



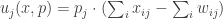
Proposition: The allocation
Proof: First notice that being a market equilibrium directly implies that all “original” players best-reply in the associated game. It also implies that 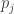
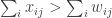
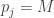
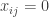
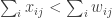

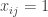
At this point it is easy to see that the game we just defined is socially concave: for an “original” player 
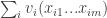

So we now close the loop: to effectively find an
ICS 2011 deadline approaching
Posted in Uncategorized, tagged Conferences on July 10, 2010| Leave a Comment »
The deadline for ICS 2011 is near: August 2nd. The conference itself will take place in Beijing on January 7-9, 2011. From the website:
Innovations in Computer Science (ICS) is a new conference in theoretical computer science (TCS), broadly construed. ICS seeks to promote research that carries a strong conceptual message (e.g., introducing a new concept or model, opening a new line of inquiry within traditional or cross-disciplinary areas, or introducing new techniques or new applications of known techniques). ICS welcomes all submissions, whether aligned with current TCS research directions or deviating from them.
The inaugural year of the conference has drawn much discussion (here, here, here, here, here, and my own here), has had many cs/econ-related papers, and seems to have been quite interesting. This year too, the conference offers financial support:
ITCS will provide full support for one author of each accepted paper, including air ticket (economy airfare at the minimum of the amount), hotel lodging (up to 4 nights), and registration fee.
WINE 2010
Posted in Uncategorized, tagged Conferences on July 10, 2010| Leave a Comment »
Amin Saberi asked me to post the following announcement for WINE 2010:
The Workshop on Internet & Network Economics (WINE) is an
interdisciplinary forum for the exchange of ideas and results arising in the algorithmic and economic analysis of Internet and WWW. WINE 2010 is co-located with the 7th Workshop on Algorithms and Models for the Web Graph (WAW 2010) from December 13 to 17 in Stanford University. The submission deadline for regular and short papers is July 30th, 2010. For more information, see http://wine2010.stanford.edu .
I am particularly impressed with the graphics of the program committee web page. (Well, the program committee composition is impressive as well).
NSF call for proposals on CS/ECON
Posted in Uncategorized on July 6, 2010| 1 Comment »
On the heels of the report to NSF on “Research issues at the interface of Computer Science and Economics”, comes a new NSF funding program on “Interface between Computer Science and Economics & Social Sciences (ICES)”. Due date for proposals: October 5th.
