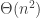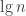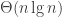As pointed out by Michael Mitzenmacher and Rakesh Vohra (who will soon carry the respectable but grammatically weird title “Penn Integrates Knowledge Professor”), the National Science Foundation SSS program is trying an intriguing new peer review method, which is based on a paper by Merrifield and Saari (Merrifield is an astronomer and Saari is a prominent social choice theorist). Vohra gives a concise summary of the proposed method:
1) There are N agents each of whom submits a proposal.
2) Each agent receives m < N proposals to review (not their own).
3) Each agent compiles a ranked list of the m she receives, placing them in the order in which she thinks the community would rank them, not her personal preferences.
4) The N ranked lists are combined to produce an optimized global list ranking all N applications.
5) Failure to carry out this refereeing duty by a set deadline leads to automatic rejection of one’s proposal.
6) Individual rankings are compared to the positions of the same m applications in the globally-optimized list. If both lists appear in approximately the same order, then proposer is rewarded by having his proposal moved a modest number of places up the final list relative to those from proposers who have not matched the community’s view as well.
An interesting detail worth mentioning is that in step 4, the lists are combined using a well-known voting rule called Borda count: Each agent awards m-k points to the proposal ranked in the k’th position. The purpose of the controversial step 6 is to incentivize good reviewing; but even Merrified and Saari worry that “this procedure will drive the allocation process toward conservative mediocrity, since referees will be dissuaded from supporting a long-shot application if they think it will put them out of line with the consensus.”
Overall I think the proposal is interesting, and certainly could be superior to the status quo. The main criticism that immediately comes to mind was also expressed by Vohra: The proposed method feels somewhat unprincipled, in that it gives no theoretical guarantees. But perhaps such a method that is actually implemented is better than impossibility results that lead nowhere — and it could be refined over time. Because criticizing is fun (and sometimes even helpful), here are two more points.
First, strategic manipulation — the bane of social choice. NSF panels are populated by people who did not submit proposals, so the incentive for manipulation is small. Under the proposed system it is not clear that you cannot increase the chances of your own proposal by placing good proposals at the bottom of your ranking. The problem is similar to classic social choice questions, but in a setting where the set of agents and set of alternatives coincide; one would want the method to be impartial, in the sense that whether your proposal is funded is independent of your submitted ranking. Recent papers deal with very similar problems: Holzman and Moulin have an Econometrica 2013 paper where the goal is to impartially select a single alternative rather than ranking the alternatives; and my TARK’11 paper with Alon, Fischer, and Tennenholtz looks at the problem of impartially selecting a subset of alternatives (we actually discuss an application to peer review in Section 5). Our mechanism is simple: If you want to select k agents, randomly partition the agents into t subsets, and select the best k/t agents from each subset only based on votes from other subsets. I know that Holzman and Moulin have tried to design (axiomatically) good mechanisms for impartial ranking and ran into impossibilities, but is ranking actually necessary? NSF just needs to select a subset (of known size) of proposals to be funded. Would I recommend our mechanism, as is, to NSF? Umm, no. But the ideas and approach could be useful.
Second, randomness. Of course, peer review is random, but usually the randomness is not so explicit. Under the current system, a panelist who happens to get a batch of bad proposals can give bad scores and reviews to all of them. Under the proposed system, an agent who is randomly assigned a batch of bad proposals has to rank one of them on top, thereby giving it m-1 points — the same number of points a proposal that is judged to be fantastic would get from beating a batch of good proposals! And there are no reviews, so essentially the number of points awarded by each reviewer is all that matters. Moreover, it is very difficult to rank a batch of bad proposals, so if you get an unlucky batch you would probably lose your potential bonus from step 6 of the proposed method. The obvious way to ameliorate these issues it to use a large value of m. The NSF program uses m=7, which on the one hand seems too small to prevent randomness from playing a pivotal role, and on the other hand seems very large as each proposal is read by seven people (instead of just four today). Increasing m would make the reviewing load unbearable.
That said, kudos to the NSF for experimenting with new peer review methods. I expect that now the NSF will have to find a way to review a wave of proposals about how to review NSF proposals.
Update June 11 10:10am EST: Here is one possible solution to the strategic manipulation problem, which gives some kind of theoretical guarantee. The desired property is that a manipulator cannot improve the position of his own proposal in the global ranking by reporting a ranking of the m proposals in his batch that is different from the ranking of these m proposals based on others’ votes. Agents are penalized for bad reviewing according to the maximum displacement distance between their ranking and the others’ aggregate ranking, i.e., the maximum difference between the position of a proposal in one ranking and the position of the same proposal in the other ranking. By pushing a proposal x down in his ranking, a manipulator’s own score in the global ranking (modified by the penalty) decreases by at least as many points as x’s Borda score in the global ranking, therefore the manipulator’s position in the global ranking can only decrease.
Read Full Post »