Perhaps the first complexity question regarding equilibria that a Computer Scientist can ask is how difficult — computationally — is it to find a pure Nash equilibrium of a given game, or report that none exists.
In the simple setting, the  -player game is given by it’s utility functions, each of them given as a table of size
-player game is given by it’s utility functions, each of them given as a table of size  of numbers (where we assume for simplicity that each player has a strategy space of size
of numbers (where we assume for simplicity that each player has a strategy space of size  .) By going over all possible possible strategy profiles and checking for each of them whether some player can gain by deviating we get an efficient algorithm. (Easy exercise: The running time of this algorithm is
.) By going over all possible possible strategy profiles and checking for each of them whether some player can gain by deviating we get an efficient algorithm. (Easy exercise: The running time of this algorithm is 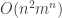 — improve it to linear in the input size, i.e to
— improve it to linear in the input size, i.e to  .)
.)
This, however, is not the end of the story. In many cases, we really have a “very large” game, and we would like to find an equilibrium in time which is significantly sub-linear in the size of the game’s utility tables. How can we even talk about getting sub-linear time algorithms? We need to read the input — don’t we? There are two standard ways in Computer Science to talk about this question. The concrete complexity approach assumes that the utility tables are given by some of “black box” which can answer queries of a certain type (e.g. given a strategy profile  , can return the value of
, can return the value of  as a single atomic operation). The set of queries that the black box supports will of course determine what can be done efficiently in this model. The Turing-Machine complexity approach will consider concise representations of the utility functions, whose length is significantly less than the full size of the tables, and expect the algorithm to find an answer in time that is polynomial in the size of the concise input. This of course gives different algorithmic problems for different concise representations.
as a single atomic operation). The set of queries that the black box supports will of course determine what can be done efficiently in this model. The Turing-Machine complexity approach will consider concise representations of the utility functions, whose length is significantly less than the full size of the tables, and expect the algorithm to find an answer in time that is polynomial in the size of the concise input. This of course gives different algorithmic problems for different concise representations.
In the rest of this post I will present the basic study of the complexity of finding a pure Nash equilibrium in these models (for general games as well as some special cases.) These basics are often overlooked as they are shadowed by the meaty PLS-completeness results and PPAD-completeness results, but I prefer talking about the basics even though these contains no “significant” proofs.
Black Box Complexity
In the variant here we assume that we get “black boxes”, one for each player, that can answer utility queries: given a strategy profile return . Another variant we can consider would also allow asking best-reply queries: given a strategy profile of the others  , return the best-reply
, return the best-reply 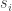 of player
of player  . (Where we would need to specify how ties are handled.) We will concentrate on cases where is not too large and we allow the running time to be polynomial in , even though in some cases we could think about running in time which is logarithmic in — the length needed to represent a strategy of a player. In these situations, as a best-reply query can easily be simulated by utility queries to all possible values of , adding a best-reply query doesn’t significantly change the power of the model. (One can imagine even more queries to ask from the black-box, and the ultimate in this direction would be t allow asking any question about
. (Where we would need to specify how ties are handled.) We will concentrate on cases where is not too large and we allow the running time to be polynomial in , even though in some cases we could think about running in time which is logarithmic in — the length needed to represent a strategy of a player. In these situations, as a best-reply query can easily be simulated by utility queries to all possible values of , adding a best-reply query doesn’t significantly change the power of the model. (One can imagine even more queries to ask from the black-box, and the ultimate in this direction would be t allow asking any question about  , but only about a single for each query. This model turns out to be equivalent to the communication complexity model.)
, but only about a single for each query. This model turns out to be equivalent to the communication complexity model.)
We will consider not only general games, but also two sub-classes of games that are known to always have a pure-Nash equilibrium: Dominance-solvable games (those where iterated elimination of strictly dominated strategies leaves a single strategy profile), and Potential Games. For motivation it is best to start with a “good” algorithm, that finds a pure Nash equilibrium in all Dominance-solvable games:
- Let be an arbitrary initial strategy profile
- Repeat
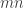 times
times
- For all players
 do
do
 best reply of to .
best reply of to .
The total running time of this algorithm is 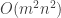 operations (which include utility queries to the black box, where each best-reply calculation is implemented via utility queries.) The interesting fact is that this algorithm always ends with a pure Nash equilibrium — as long as the game is dominance-solvable. (Idea of easy proof: a strategy that was eliminated in the
operations (which include utility queries to the black box, where each best-reply calculation is implemented via utility queries.) The interesting fact is that this algorithm always ends with a pure Nash equilibrium — as long as the game is dominance-solvable. (Idea of easy proof: a strategy that was eliminated in the  ‘th step of the strategy elimination process can never be used after iterations of the outer loop of this algorithm.) What is remarkable about this running time is that it is exponentially smaller than the “input size”, as each black box contains numbers in it.
‘th step of the strategy elimination process can never be used after iterations of the outer loop of this algorithm.) What is remarkable about this running time is that it is exponentially smaller than the “input size”, as each black box contains numbers in it.
Can such an efficient algorithm — whose running time is polynomial in and — be found for other games? For potential games? Maybe even this algorithm — just repeated best-replying — will do the trick? It is not difficult to see for general games repeated-best replying may loop infinitely even if some pure Nash equilibrium exists. For potential games, almost by definition, every sequence of best-replies will indeed terminate with a pure Nash equilibrium. (In fact, ordinal potential games are exactly those games where every sequence of better-replies terminates.) But how long can this take? Unfortunately, exponential time. (Exercise: find an exact potential game with players each having two strategies, where starting from some strategy profile , every sequence of best-replies requires exponential time to reach a Nash equilibrium.)
So, can there be another efficient algorithm for general games or for potential games? A simple observation is that in a potential game where the potential function has polynomial-sized range, any best-reply sequence will terminate withing this polynomial number of steps. Can this be generalized even further? One can formally prove a negative answer — a lower bound. One of the simplest formalisms for this is using an “adversary argument”: instead of first choosing a game and then letting the algorithm access the utility functions via the black boxes, the adversary will make-up the game as he goes along. Each time the hypothetical algorithm makes a query to the black-box, the adversary will answer it in some way that he thinks will be least helpful to the algorithm — making sure that for as long as possible the algorithm does not have sufficient information as to provide an answer. The idea about this technique is that if the adversary can pull this off — i.e. keep answering in a consistent way such that a single answer is still not guaranteed — then there must be some fixed game for which the hypothetical algorithm was not able to produce a correct answer in time — exactly the game that is still consistent with the adversary’s answers.
For the case of general games it is easy to provide such an adversary. Let the adversary fix in his mind some game without any pure Nash equilibrium. (For concreteness, say, 2 players playing matching pennies, and another 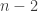 players not caring at all, but still having two strategies each. This gives a game with
players not caring at all, but still having two strategies each. This gives a game with  strategy profiles, whose structure is just many multiple copies of the 2×2 game of matching pennies.) Whenever the algorithm makes a query, the adversary will just answer with the value of the fixed game. Clearly the algorithm can never find a pure Nash equilibrium since none exists. The point is that the algorithm cannot decide that no Nash equilibrium exists before making at least queries. If even a single strategy profile was not queried, then it could be that at that strategy profile all players get high utility (where “high” is anything higher than any value in the original game) and thus it is a Nash equilibrium.
strategy profiles, whose structure is just many multiple copies of the 2×2 game of matching pennies.) Whenever the algorithm makes a query, the adversary will just answer with the value of the fixed game. Clearly the algorithm can never find a pure Nash equilibrium since none exists. The point is that the algorithm cannot decide that no Nash equilibrium exists before making at least queries. If even a single strategy profile was not queried, then it could be that at that strategy profile all players get high utility (where “high” is anything higher than any value in the original game) and thus it is a Nash equilibrium.
For the case of potential games the adversary must be somewhat more clever. We will consider an player game where each player has two strategies and thus the space of strategy profiles is the -dimensional Boolean hypercube. Our adversary will produce an exact potential game, as will be evident by the fact that all players will have exactly the same utility at each strategy profile. In such cases a pure Nash equilibrium is simply a local maximum of this utility function. Let us start with the basic idea, that does not quite do the job: At the ‘th query of the algorithm,  , the adversary will answer
, the adversary will answer  . The idea is that the algorithm cannot find any Nash equilibrium this way since a strategy profile can be declared to be such only if all of its neighbors (in the Boolean hypercube — corresponding to the possible deviations by a single player) were already queried to have a lower utility than the vertex itself. Since the adversary keeps answering with increasing values, the only way that this can happen is if the algorithm first “closes up” a strategy profile (vertex in the hypercube) by first asking all of its neighbors and only then the enclosed vertex. So to fix it, we’ll improve the adversary: when asked a query , the adversary will look at the set of un-accessed vertices of the hypercube and see whether any vertices are left disconnected from the “rest of the hypercube”. Specifically, let us call a vertex “compromised” if its connected component (after removing all queries
. The idea is that the algorithm cannot find any Nash equilibrium this way since a strategy profile can be declared to be such only if all of its neighbors (in the Boolean hypercube — corresponding to the possible deviations by a single player) were already queried to have a lower utility than the vertex itself. Since the adversary keeps answering with increasing values, the only way that this can happen is if the algorithm first “closes up” a strategy profile (vertex in the hypercube) by first asking all of its neighbors and only then the enclosed vertex. So to fix it, we’ll improve the adversary: when asked a query , the adversary will look at the set of un-accessed vertices of the hypercube and see whether any vertices are left disconnected from the “rest of the hypercube”. Specifically, let us call a vertex “compromised” if its connected component (after removing all queries 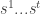 from the hypercube) has size strictly less than
from the hypercube) has size strictly less than 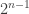 (half the hypercube). What our adversary will do is go over all newly compromised vertices, fixing their values in an order that increases from the farthest away from to itself. This way a vertex is never assigned a value after all of its neighbors have, and thus no vertex can be guaranteed to be a Nash equilibrium until all vertices of the hypercube are either queried or compromised. The only question is how many queries does this take? Let
(half the hypercube). What our adversary will do is go over all newly compromised vertices, fixing their values in an order that increases from the farthest away from to itself. This way a vertex is never assigned a value after all of its neighbors have, and thus no vertex can be guaranteed to be a Nash equilibrium until all vertices of the hypercube are either queried or compromised. The only question is how many queries does this take? Let  be the set of queries and
be the set of queries and  be the set of all vertices compromised by , how large does have to be for the union to be at least half of the whole hypercube? Combinatorially, must contain all of ‘s neighbors in the hypercube. This leads us to ask for smallest possible size of the set of neighbors of a set of vertices in the hypercube — known as the isoperimetric problem for the Boolean hypercube. This question is completely solved (see chapter 16 of Bollobas), and in particular it is known that for any subset of at most half of the hypercube, the size of the set of its neighbors is at least
be the set of all vertices compromised by , how large does have to be for the union to be at least half of the whole hypercube? Combinatorially, must contain all of ‘s neighbors in the hypercube. This leads us to ask for smallest possible size of the set of neighbors of a set of vertices in the hypercube — known as the isoperimetric problem for the Boolean hypercube. This question is completely solved (see chapter 16 of Bollobas), and in particular it is known that for any subset of at most half of the hypercube, the size of the set of its neighbors is at least  fraction of original set’s size. This means that
fraction of original set’s size. This means that 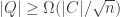 , which implies that
, which implies that  — an exponential lower bound for the worst case running time of any algorithm that finds a pure Nash equilibrium for all potential games. An immediate corollary is that there may be best-reply paths of this exponential length.
— an exponential lower bound for the worst case running time of any algorithm that finds a pure Nash equilibrium for all potential games. An immediate corollary is that there may be best-reply paths of this exponential length.
Turing-Machine complexity
We now move to the alternative way of accessing a “large” game, that of representing it concisely. Clearly not every game has such a concise representation, but can we at least find and equilibrium efficiently for those that do? Also, different representations may require different complexities — which concise representation should we consider? The first one we will look at is the general representation of a black box by the code of a procedure, equivalently by a description of Turing machine. However, we only want to consider TMs that run efficiently, e.g. in polynomial time, or alternatively count the running time of the TM as part of the input size. The usual formalism for giving such a TM as input, is the equivalent requirement of a Boolean circuit that computes the black-box queries, and this will be our first concise representation:
Input: boolean circuits, each computing a function 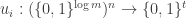 , where the input of each circuit is the index of each player’s strategy and the output of each circuit is interpreted as a -bit long integer specifying the utility.
, where the input of each circuit is the index of each player’s strategy and the output of each circuit is interpreted as a -bit long integer specifying the utility.
Output (Decision version): does this game have a pure Nash equilibrium?
We would expect the running time to be polynomial in the input size:  , and the total size of the circuits. As before let us concentrate on cases where is not too large (i.e. also polynomial in these parameters).
, and the total size of the circuits. As before let us concentrate on cases where is not too large (i.e. also polynomial in these parameters).
So what is the complexity of this problem? Generally speaking, the state of complexity theory is such that we get essentially no algorithmically-useful information from the circuit representation. Thus, we would expect a polynomial time algorithm to exist for this generic representation only if such existed in the black-box model — which is doesn’t. In this world we can easily prove an NP-completeness result.
Theorem: Existence of a pure Nash equilibrium in a game given by boolean circuits (as above) is NP-complete.
Proof: Containment in NP is by guessing the equilibrium point, and then verifying it by checking all possible deviations for every player. (This is the only place where we used being small, otherwise the problem seems to be  -complete). To prove NP-hardness we will provide a reduction from 3-SAT (I lost the reference for this reduction). All players will have two strategies: 0 and 1. For each variable we will have a player whose utility function is a constant 0. For each clause we will have an additional player whose utility function gives him 1 if his strategy is the OR of its literals. We will then have two additional “top” players whose utilities are as follows: if all clause players play 1, then both of these players get utility 1 whatever they play; otherwise, these players play “matching pennies” between themselves. Note that in a pure Nash equilibrium, the variable players can play anything, the clause players must faithfully compute the clause values, and then the two “top” players can be in equilibrium if and only if all clause values are 1.
-complete). To prove NP-hardness we will provide a reduction from 3-SAT (I lost the reference for this reduction). All players will have two strategies: 0 and 1. For each variable we will have a player whose utility function is a constant 0. For each clause we will have an additional player whose utility function gives him 1 if his strategy is the OR of its literals. We will then have two additional “top” players whose utilities are as follows: if all clause players play 1, then both of these players get utility 1 whatever they play; otherwise, these players play “matching pennies” between themselves. Note that in a pure Nash equilibrium, the variable players can play anything, the clause players must faithfully compute the clause values, and then the two “top” players can be in equilibrium if and only if all clause values are 1.
The next succinct representation we consider is one that aims to take advantage of the fact that in many games while there are many players, each player’s utility only depends on the strategies of a few others and not on everyone’s strategies. In such cases, we can represent the utility of each player as a full table of only the relevant players’ strategies. In such games an important structure is obtained by looking at the graph (or digraph) specifying for each two players whether the utility of one depends on the strategy played by the other. So here is the equilibrium problem using this “graphical games” succinct representation:
Input: A graph  and for each vertex in it, a table
and for each vertex in it, a table  , where
, where 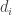 is the degree of vertex , and the table specifies the utility of player as a function of his strategy as well as those of his neighbors.
is the degree of vertex , and the table specifies the utility of player as a function of his strategy as well as those of his neighbors.
Output (Decision version): does this game have a pure Nash equilibrium?
We would expect the running time to be polynomial in the the total size of the tables, i.e polynomial in and in  , where
, where  .
.
However just a tiny variation of the NP-completeness proof above shows that this problem in NP-complete too. The only players in the reduction above who had degree more than 3 are the two top players who were “computing” the “AND” of all the clauses. To get a reduction where all players have degree at most 3, we will add an additional player for each clause who will compute the “and” of this clause with all preceding ones. This will be done by giving him utility 1 if his strategy is indeed the “and” of the original clause-player of his clause and the new-clause-player of the preceding clause (and 0 otherwise). Now the two “top” players will just need to depend on the new-clause-player of the last clause as they did before (either always wining or playing matching pennies). Thus we get:
Theorem: Existence of a pure Nash equilibrium in graphical games (as above) is NP-complete.
A nice exercise is to exhibit a polynomial time algorithm for the special case that when the graph is in fact a tree.
Now let us move to the special case of exact potential games. The problem specification (input and output) is exactly as defined above where the utility functions are given as Boolean circuits, except that we are guaranteed that the utility functions are those of an exact potential game. (This condition may not be easy to verify in general, but our algorithm may take it as an assumption.) We know that a pure equilibrium is exactly a local maximum of the potential function. This potential function is uniquely defined, up to an additive constant, by the given utility functions: once the value of the potential function is known for some profile, 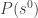 , we can change, in turn each
, we can change, in turn each 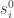 to an arbitrary and the difference is completely specified by . Thus the potential function is defined by
to an arbitrary and the difference is completely specified by . Thus the potential function is defined by 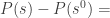
![\sum_{i=1}^n [ P(s^0_1 ... s^0_i, s_{i+1} ... s_n) - P(s^0_1 ... s^0_{i-1}, s_i, ..., s_n)] =](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi%3D1%7D%5En+%5B+P%28s%5E0_1+...+s%5E0_i%2C+s_%7Bi%2B1%7D+...+s_n%29+-+P%28s%5E0_1+...+s%5E0_%7Bi-1%7D%2C+s_i%2C+...%2C+s_n%29%5D+%3D+&bg=ffffff&fg=333333&s=0&c=20201002)
![\sum_{i=1}^n [u_i(s^0_1 ... s^0_i, s_{i+1} ... s_n) - u_i(s^0_1 ... s^0_{i-1}, s_i, ..., s_n)]](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi%3D1%7D%5En+%5Bu_i%28s%5E0_1+...+s%5E0_i%2C+s_%7Bi%2B1%7D+...+s_n%29+-+u_i%28s%5E0_1+...+s%5E0_%7Bi-1%7D%2C+s_i%2C+...%2C+s_n%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) . We see that the problem of finding a pure Nash equilibrium for potential games is equivalent to that of finding a local maximum of a given Boolean circuit, where “locality” is given by switching the values of one of the sets of
. We see that the problem of finding a pure Nash equilibrium for potential games is equivalent to that of finding a local maximum of a given Boolean circuit, where “locality” is given by switching the values of one of the sets of  bits in our problem definition. (Proof: the expression above is efficiently computable and thus our problem is no harder, and on the other hand a special case of our problem is where all ‘s are identical in which case our problem is equivalent to finding a local maximum.)
bits in our problem definition. (Proof: the expression above is efficiently computable and thus our problem is no harder, and on the other hand a special case of our problem is where all ‘s are identical in which case our problem is equivalent to finding a local maximum.)
Now let us say a few words about the complexity of this local-maximum problem. First, syntactically speaking we have an “NP search problem”: on input  (the utility functions) the task is to find some solution
(the utility functions) the task is to find some solution  (strategy profile) that satisfies
(strategy profile) that satisfies  ( is a local maximum of ), where
( is a local maximum of ), where  is computable in polynomial time. The general class of such search problems is termed FNP, and in our case we are talking about problems with a guarantee that such a always exists, a subclass termed TFNP. Now, semantically, there are various other problems that have a similar flavor of finding a local maximum (or minimum), and this class of problems, a subset of TFNP, was termed PLS (polynomial local search). Some examples of such problems come from attempting to formalize what various local-improvement search heuristics obtain: suppose that you attempt finding a short traveling salesman route by gradually trying to switch the locations of pairs of cities along the route. What do you get? How long will this take? The general class of problems in PLS is defined as those having polynomial-time computable procedures specifying a neighborhood relation and a quality score over solutions where the problem is to define a solution which is a local minimum (or maximum). By these definitions, our problem is in this class PLS, and in fact the generic nature of our problem makes it PLS-complete. So what does this PLS-completeness mean? It means that the complexity of our problem is similar to the hardest problems in this class which seem to have intermediate difficulty between P and NP. We do not know a polynomial time algorithm for them (and such an algorithm will require significantly new techniques since it doesn’t “relativize”), nor or they likely to be NP-complete (since that would also imply NP=coNP).
is computable in polynomial time. The general class of such search problems is termed FNP, and in our case we are talking about problems with a guarantee that such a always exists, a subclass termed TFNP. Now, semantically, there are various other problems that have a similar flavor of finding a local maximum (or minimum), and this class of problems, a subset of TFNP, was termed PLS (polynomial local search). Some examples of such problems come from attempting to formalize what various local-improvement search heuristics obtain: suppose that you attempt finding a short traveling salesman route by gradually trying to switch the locations of pairs of cities along the route. What do you get? How long will this take? The general class of problems in PLS is defined as those having polynomial-time computable procedures specifying a neighborhood relation and a quality score over solutions where the problem is to define a solution which is a local minimum (or maximum). By these definitions, our problem is in this class PLS, and in fact the generic nature of our problem makes it PLS-complete. So what does this PLS-completeness mean? It means that the complexity of our problem is similar to the hardest problems in this class which seem to have intermediate difficulty between P and NP. We do not know a polynomial time algorithm for them (and such an algorithm will require significantly new techniques since it doesn’t “relativize”), nor or they likely to be NP-complete (since that would also imply NP=coNP).
A special case of potential games is that of network congestion games. In these we are given a (directed) graph, with pairs of vertices  in it and, for each edge
in it and, for each edge  , a sequence of
, a sequence of  costs:
costs:  . This is a succinct representation of a congestion game: player ‘s set of strategies is the set of paths in the graph from
. This is a succinct representation of a congestion game: player ‘s set of strategies is the set of paths in the graph from  to
to  , and the cost (negative utility) of a player is the sum of
, and the cost (negative utility) of a player is the sum of 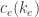 over all edges in his path, where
over all edges in his path, where 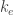 is the number of players whose strategy (path) contains the edge . Network congestion games are exact potential games, and have a pure Nash equilibrium. Finding such an equilibrium turns out to be PLS-complete too, although this requires a complicated reduction.
is the number of players whose strategy (path) contains the edge . Network congestion games are exact potential games, and have a pure Nash equilibrium. Finding such an equilibrium turns out to be PLS-complete too, although this requires a complicated reduction.
Read Full Post »

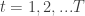


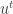


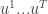
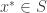




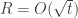





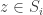
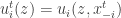
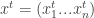


![E_{x \sim D} [u_i(x)] \ge E_{x_{-i} \sim D_{-i}} [u_i(x^*_i,x_{-i})]](https://s0.wp.com/latex.php?latex=E_%7Bx+%5Csim+D%7D+%5Bu_i%28x%29%5D+%5Cge+E_%7Bx_%7B-i%7D+%5Csim+D_%7B-i%7D%7D+%5Bu_i%28x%5E%2A_i%2Cx_%7B-i%7D%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)


![E_{x \sim D} [u_i(x)] \ge E_{x_{-i} \sim D_{-i}} [u_i(x^*_i,x_{-i})] - \epsilon](https://s0.wp.com/latex.php?latex=E_%7Bx+%5Csim+D%7D+%5Bu_i%28x%29%5D+%5Cge+E_%7Bx_%7B-i%7D+%5Csim+D_%7B-i%7D%7D+%5Bu_i%28x%5E%2A_i%2Cx_%7B-i%7D%29%5D+-+%5Cepsilon&bg=ffffff&fg=333333&s=0&c=20201002)



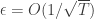

is convex in
.
is a concave function of
![\hat{x} = E_{x \sim D} [x]](https://s0.wp.com/latex.php?latex=%5Chat%7Bx%7D+%3D+E_%7Bx+%5Csim+D%7D+%5Bx%5D&bg=ffffff&fg=333333&s=0&c=20201002)
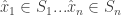
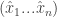
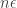
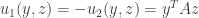




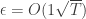
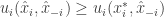

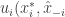
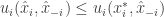
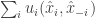
![\hat{x} = E[ x]](https://s0.wp.com/latex.php?latex=%5Chat%7Bx%7D+%3D+E%5B+x%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\sum_i u_i(\hat{x}_i,\hat{x}_{-i}) \ge E[\sum_i u_i(x_i, x_{-i})]=\sum_i E[u_i(x_i, x_{-i})]](https://s0.wp.com/latex.php?latex=%5Csum_i+u_i%28%5Chat%7Bx%7D_i%2C%5Chat%7Bx%7D_%7B-i%7D%29+%5Cge+E%5B%5Csum_i+u_i%28x_i%2C+x_%7B-i%7D%29%5D%3D%5Csum_i+E%5Bu_i%28x_i%2C+x_%7B-i%7D%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![E[u_i(x_i, x_{-i})] \ge E[u_i(x^*_i,x_{-i})]](https://s0.wp.com/latex.php?latex=E%5Bu_i%28x_i%2C+x_%7B-i%7D%29%5D+%5Cge+E%5Bu_i%28x%5E%2A_i%2Cx_%7B-i%7D%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![E[u_i(x^*_i,x_{-i})] \ge u_i(x^*_i,\hat{x}_{-i})](https://s0.wp.com/latex.php?latex=E%5Bu_i%28x%5E%2A_i%2Cx_%7B-i%7D%29%5D+%5Cge+u_i%28x%5E%2A_i%2C%5Chat%7Bx%7D_%7B-i%7D%29&bg=ffffff&fg=333333&s=0&c=20201002)
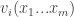
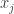

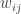

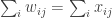
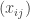
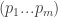

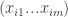


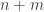



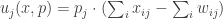
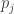
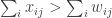
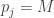
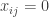
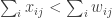

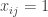

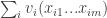


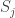 is the set of strategies of player
is the set of strategies of player 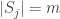 for all
for all  -bit numerator and denominator. Can a mixed Nash equilibrium be found by communicating significantly less than
-bit numerator and denominator. Can a mixed Nash equilibrium be found by communicating significantly less than 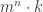 bits — the size of each utility function? Maybe it can be done by communicating only a polynomial (in
bits — the size of each utility function? Maybe it can be done by communicating only a polynomial (in 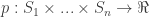 that satisfies linear inequalities of the following form: for every player
that satisfies linear inequalities of the following form: for every player  :
:  , where the sum ranges over all strategy profiles
, where the sum ranges over all strategy profiles  on
on  , it must find a constraint, in our case a player
, it must find a constraint, in our case a player  bits of communication. When the algorithm terminates — after a polynomial number of steps (polynomial in
bits of communication. When the algorithm terminates — after a polynomial number of steps (polynomial in  is an arbitrary parameter.
is an arbitrary parameter. and his first with probability
and his first with probability 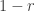 . This family of games suffices for giving a tight lower bound for the special case of two-player (
. This family of games suffices for giving a tight lower bound for the special case of two-player ( ) bi-strategy (
) bi-strategy ( ) games.
) games. .
.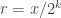 , for integer
, for integer 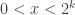 since each of these games has a different (unique) answer giving
since each of these games has a different (unique) answer giving  different such answers, which thus requires at least
different such answers, which thus requires at least  , and then invoke the previous bound.
, and then invoke the previous bound. -player game, with the following properties:
-player game, with the following properties: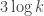 players has 2 strategies. The utilities of each of these are constants not depending on the original game at all.
players has 2 strategies. The utilities of each of these are constants not depending on the original game at all. players are fixed constants independent of the game.
players are fixed constants independent of the game.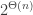 .
. players.
players.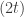 -player win-lose bi-strategy games such that the unique Nash equilibrium has, for each
-player win-lose bi-strategy games such that the unique Nash equilibrium has, for each  , players
, players 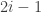 and
and 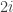 choosing their first strategy with probability exactly
choosing their first strategy with probability exactly  .
.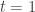 , this is exactly “matching pennies”, i.e. the
, this is exactly “matching pennies”, i.e. the  game described above for
game described above for 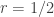 (after scaling by a factor of 2). Now for the induction step we start with
(after scaling by a factor of 2). Now for the induction step we start with 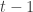 pairs of players as promised by the induction hypothesis, and we keep these players’ utilities completely independent of the soon to be introduced 2 new players, so we know that in every Nash equilibrium of the currently constructed
pairs of players as promised by the induction hypothesis, and we keep these players’ utilities completely independent of the soon to be introduced 2 new players, so we know that in every Nash equilibrium of the currently constructed 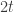 -player game these will still mix exactly as stated by the fact above for
-player game these will still mix exactly as stated by the fact above for  -player game choose their first strategy with probability
-player game choose their first strategy with probability 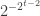 . The point is that with these players in place, we can easily simulate the
. The point is that with these players in place, we can easily simulate the  . To simulate a “
. To simulate a “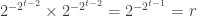 ) and 0 otherwise, while to define a
) and 0 otherwise, while to define a 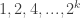 , equivalently, after scaling, in the range
, equivalently, after scaling, in the range  . This is done by adding to the original players
. This is done by adding to the original players  players as defined in the construction above. We can now replace each utility of the original players of the form
players as defined in the construction above. We can now replace each utility of the original players of the form 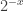 where
where  with a utility of 1 whenever, for every
with a utility of 1 whenever, for every 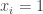 , new player
, new player 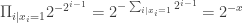 , as needed.
, as needed.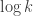 bi-strategy players, paired into
bi-strategy players, paired into  independent “matching pennies” games, and thus each of them always evenly mixes between his two strategies. To simulate a utility of
independent “matching pennies” games, and thus each of them always evenly mixes between his two strategies. To simulate a utility of  in the original game, we give, in the new game, a utility of
in the original game, we give, in the new game, a utility of  whenever the
whenever the 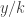 , completing the simulation (as the scaling by a factor of
, completing the simulation (as the scaling by a factor of 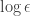 . (See a
. (See a  .
.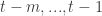 . We introduce and study a simple model of market evolution, where strategies impact the market by their decision to buy or sell. We show that the effect of optimal strategies using memory
. We introduce and study a simple model of market evolution, where strategies impact the market by their decision to buy or sell. We show that the effect of optimal strategies using memory 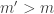 to make a bigger profit than was initially possible. We suggest ours as a framework to rationalize the technological arms race of quantitative trading firms.
to make a bigger profit than was initially possible. We suggest ours as a framework to rationalize the technological arms race of quantitative trading firms. and then the players somehow interact until they find an equilibrium of the game
and then the players somehow interact until they find an equilibrium of the game  defined by their joint utilities. The analysis here abstracts away the different incentives of the players (the usual focus of attention in game theory) and is only concerned with the amount of information transfer required between the players. I.e., we treat this as a purely distributed computation question where the input
defined by their joint utilities. The analysis here abstracts away the different incentives of the players (the usual focus of attention in game theory) and is only concerned with the amount of information transfer required between the players. I.e., we treat this as a purely distributed computation question where the input  is distributed between the players who all just want to jointly compute an equilibrium point. We assume perfect cooperation and prior coordination between the players, i.e. that all follow a predetermined protocol that was devised to compute the required output with minimum amount of communication. The advantage of this model is that it provides lower bounds for all sorts of processes and dynamics and that eventually should reach equilibria: if even under perfect cooperation much communication is required for reaching equilibrium, then certainly whatever individual strategy each player follows, convergence to equilibrium cannot happen quickly.
is distributed between the players who all just want to jointly compute an equilibrium point. We assume perfect cooperation and prior coordination between the players, i.e. that all follow a predetermined protocol that was devised to compute the required output with minimum amount of communication. The advantage of this model is that it provides lower bounds for all sorts of processes and dynamics and that eventually should reach equilibria: if even under perfect cooperation much communication is required for reaching equilibrium, then certainly whatever individual strategy each player follows, convergence to equilibrium cannot happen quickly. -bit string,
-bit string, 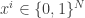 . The usual focus is on the two-player case,
. The usual focus is on the two-player case, 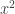 . The joint goal of these players is to compute the value of
. The joint goal of these players is to compute the value of  where
where  is some predetermined function. As
is some predetermined function. As 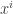 , the players will need to communicate with each other in order to do so (we will use “broadcasting” rather than player-to-player channels), and they will do so according to a predetermined protocol. Such a protocol specifies when each of them speaks and what he says, where the main point is that each player’s behavior must be a function of his own input as well as what was broadcast so far. We will assume that all communication is in bits (any finite alphabet can be represented in bits). The communication complexity of
, the players will need to communicate with each other in order to do so (we will use “broadcasting” rather than player-to-player channels), and they will do so according to a predetermined protocol. Such a protocol specifies when each of them speaks and what he says, where the main point is that each player’s behavior must be a function of his own input as well as what was broadcast so far. We will assume that all communication is in bits (any finite alphabet can be represented in bits). The communication complexity of  is the minimum amount of bits of communication that a protocol for
is the minimum amount of bits of communication that a protocol for  and Bob holds
and Bob holds 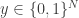 . They need to determine whether there exists an index
. They need to determine whether there exists an index 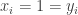 . If we view
. If we view  and
and 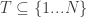 , then we are asking whether
, then we are asking whether  .
. lower bound also applies to randomized protocols, but the proof for the randomized case is harder, while the proof for the deterministic case is easy.
lower bound also applies to randomized protocols, but the proof for the randomized case is harder, while the proof for the deterministic case is easy.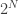 different input pairs of the form
different input pairs of the form  (these are the “maximal disjoint” inputs). We will show that for no two of these input pairs can the protocol produce the same communication transcript (i.e. the exact same sequence of bits is sent throughout the protocol). It follows that the protocol must have at least
(these are the “maximal disjoint” inputs). We will show that for no two of these input pairs can the protocol produce the same communication transcript (i.e. the exact same sequence of bits is sent throughout the protocol). It follows that the protocol must have at least 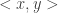 and
and 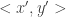 have the same transcript? Had we been in a situation that
have the same transcript? Had we been in a situation that 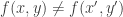 then we would know that the transcripts must be different since the protocol must output a different answer in the two cases; however in our case all “maximal disjoint” input pairs give the same answer: “disjoint”. We use the structure of communication protocols — that each player’s actions can only depend on his own input (and on the communication so far) — to show that if
then we would know that the transcripts must be different since the protocol must output a different answer in the two cases; however in our case all “maximal disjoint” input pairs give the same answer: “disjoint”. We use the structure of communication protocols — that each player’s actions can only depend on his own input (and on the communication so far) — to show that if 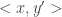 has the same transcript too (and so does
has the same transcript too (and so does  ). Consider the players communicating on inputs
). Consider the players communicating on inputs 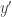 cannot distinguish it from the case
cannot distinguish it from the case 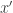 and
and 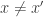 there must be an index
there must be an index 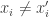 . If
. If  and
and 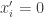 then
then  and
and 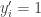 in which case
in which case  and
and  then
then 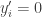 and
and 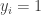 in which case
in which case  , where the
, where the  do
do
 numbers for each player. Can some protocol like this be designed for all games that have a pure Nash equilibrium? The basic answer in no:
numbers for each player. Can some protocol like this be designed for all games that have a pure Nash equilibrium? The basic answer in no: bits of communication.
bits of communication. .
.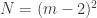 . The idea is very simple: Alice will build a utility matrix
. The idea is very simple: Alice will build a utility matrix  by filling it with the values of its bit string
by filling it with the values of its bit string  from
from 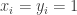 will turn out to be a Nash equilibrium since both players get the highest utility possible in this matrix. For this idea to formally work, we just need to make sure that no other cell is a Nash equilibrium. This can be done in one of several ways (and different ones are used in the C&S and H&M papers), the simplest of which is adding two more rows and columns as follows:
will turn out to be a Nash equilibrium since both players get the highest utility possible in this matrix. For this idea to formally work, we just need to make sure that no other cell is a Nash equilibrium. This can be done in one of several ways (and different ones are used in the C&S and H&M papers), the simplest of which is adding two more rows and columns as follows:")
 -bit long vectors.
-bit long vectors. . (Exercise: show that the randomized communication complexity in this case is
. (Exercise: show that the randomized communication complexity in this case is 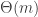 .) As
.) As 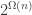 lower bound for constant
lower bound for constant 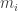 possible strategies, each player has a utility function
possible strategies, each player has a utility function  . We will denote by
. We will denote by  the set of probability distributions on
the set of probability distributions on  and for
and for 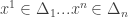 we use
we use 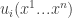 as a shorthand for
as a shorthand for 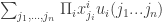 , the expected value of
, the expected value of  where each
where each  is chosen at random according to the probability
is chosen at random according to the probability  then the Nash equilibria may all be irrational numbers. We thus cannot just ask our algorithm to output a Nash equilibrium since it may not have a finite representation and so we need to settle for approximation in order to even define the “exact” problem. So here is the carefully stated common definition of the Nash equilibrium computation problem:
then the Nash equilibria may all be irrational numbers. We thus cannot just ask our algorithm to output a Nash equilibrium since it may not have a finite representation and so we need to settle for approximation in order to even define the “exact” problem. So here is the carefully stated common definition of the Nash equilibrium computation problem: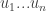 each of dimensions
each of dimensions  . For finiteness of representation, each of the
. For finiteness of representation, each of the 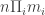 numbers in the input is a rational number given by a
numbers in the input is a rational number given by a  -digit numerator and denominator. We are also give a rational number
-digit numerator and denominator. We are also give a rational number  (with
(with 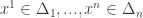 that are an
that are an 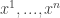 are
are 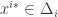 we have that
we have that  .
. .
. -digit long numerator and denominator, and thus the exact version is equivalent to the problem as stated.
-digit long numerator and denominator, and thus the exact version is equivalent to the problem as stated.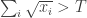
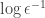 . An alternative version would be to require
. An alternative version would be to require 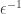 . This version is asking for a
. This version is asking for a  as the Nash equilibrium point
as the Nash equilibrium point 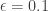 ) . As the original problem scales, for the approximation to make sense, we need to normalize
) . As the original problem scales, for the approximation to make sense, we need to normalize 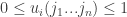 .
. where
where  is
is 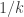 . I.e. it is a uniform distribution on a multi-set of size
. I.e. it is a uniform distribution on a multi-set of size  and fixed pure strategies
and fixed pure strategies 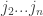 , if we chose a random
, if we chose a random  of
of ![Pr[|u_i(\tilde{x}^1,j_2,...,j_n) - u_i(x^1,j_2,...,j_n)| > \epsilon] \le e^{-\Omega(k\epsilon^2)}](https://s0.wp.com/latex.php?latex=Pr%5B%7Cu_i%28%5Ctilde%7Bx%7D%5E1%2Cj_2%2C...%2Cj_n%29+-+u_i%28x%5E1%2Cj_2%2C...%2Cj_n%29%7C+%3E+%5Cepsilon%5D+%5Cle+e%5E%7B-%5COmega%28k%5Cepsilon%5E2%29%7D&bg=ffffff&fg=333333&s=0&c=20201002) .
. is the expected value of
is the expected value of  when
when  is chosen according to
is chosen according to  , while
, while  is the average value of
is the average value of  , where
, where  , then, with high probability (due to the union bound), the previous proposition holds for all pure strategies
, then, with high probability (due to the union bound), the previous proposition holds for all pure strategies 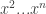 :
: is an
is an 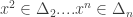 and all
and all  .
. and chooses a
and chooses a  -approximation
-approximation 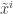 for each
for each 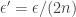 ). Since
). Since  are an approximate equilibrium, it suffices to show that changing the
are an approximate equilibrium, it suffices to show that changing the  algorithm follows simply by exhaustive search, and thus we get our algorithm.
algorithm follows simply by exhaustive search, and thus we get our algorithm.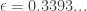 .
.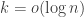 rows there exists a single column which has all 0 entries in these rows. Thus any mixed strategy that is
rows there exists a single column which has all 0 entries in these rows. Thus any mixed strategy that is  -simple cannot ensure positive value. It follows that there does not exists a
-simple cannot ensure positive value. It follows that there does not exists a  and
and  . A recent
. A recent 