
I’ve recently given a general talk about Algorithmic Mechanism Design in which, as usual, one of my motivational slides was the Braess Paradox (if you are a reader of this blog and have not seen the Braess paradox yet — stop reading this post and read about it instead). I would say that the Braess Paradox has been the most influential single intellectual motivator of the whole field of Algorithmic Game Theory. Computer Scientists love it. Economists like it, but CS/Engineering types love it. Here are some thoughts about why we, computer scientists, were so rattled by it.
The Braess paradox provides a simple example where selfish individual behavior leads to results that are socially sub-optimal. An economist can hardly be blown off his feet. The revelation that individuals may act selfishly (or as they would say, rationally) is hardly a surprise for an economist — in fact that is the basis of his field. The fact that such selfish behaviors may have externalities and can result in a sub-optimal outcome is more interesting, but the tragedy of the commons, much studied and discussed, is certainly a more devastating demonstration of this. (Aside: it seems that many undergraduate curricula in economics are so focused on perfect market scenarios that the failure of these models is hardly discussed and you need to get a graduate degree to hear about the limitations of free markets.) However, for engineers we have two revelations here. The mere suggestion that even though we design a system in some “perfect” way, someone who has control over part of the system may reasonably change it is annoying and surprising. Yes, we engineers were thinking about “bad guys” (security), about “broken systems” (distributed computing) but the fact that “ok guys” may circumvent all our designs is an annoying revelation. While the initial reaction of an engineer would be “well, if they’re not following my deisgn, then I can’t guarantee anything“, the Braess paradox also shows that one can analyze the situation under selfish behavior — an unexpected but pleasant surprise. So while economists treat the Braess paradox as just a cute example as of itself, computer scientists immediately view it as a fictional model that stands for a whole new class of examples.
The second difference of a point of view between economists and computer scientists would be about what kind of solutions for this problem should we go after. It would be clear to an economist (continuing my aside from above: at least one with a graduate degree) that in this case some kind of regulation or taxation is needed. However, an engineer or computer scientist would require a much more specific and detailed answer: exactly how much taxation? How would it depend on the network structure? On the set of requests for routing? On the delay characteristics? Economists would also be interested in some form of these questions, but the degree of specificness which would satisfy an economist is much less than what would satisfy an engineer. I would say that most economists would not immediately feel that there are interesting open problems around Braess’s paradox. Engineers and Computer Scientists would feel otherwise: we want general algorithms that will work. An analysis that is satisfying for a whole class of future scenarios. Something that we can implement, analyze, and be confident that will work in the future.
Just by itself then, the Braess paradox offers computer scientists a new set of problems (selfishness), tools to address these problems (equilibrium analysis), and challenges (analysis and algorithms for general scenarios). The appeal is clear, and the main attraction of the seminal AGT paper that introduced the Braess paradox to Computer Scientists was suggesting that the challenges can be addressed: a general analysis, for a whole class of networks, requests, and delays, is possible.
Read Full Post »

 infinitely divisible goods, and a consumer has a utility function
infinitely divisible goods, and a consumer has a utility function ![u:[0,1]^n \rightarrow \Re^+](https://s0.wp.com/latex.php?latex=u%3A%5B0%2C1%5D%5En+%5Crightarrow+%5CRe%5E%2B&bg=ffffff&fg=333333&s=0&c=20201002) specifying his utility for every bundle of goods. Importantly, we are not assuming anything on the utility function except that it is weakly monotone in each coordinate (free disposal). Given a vector of prices
specifying his utility for every bundle of goods. Importantly, we are not assuming anything on the utility function except that it is weakly monotone in each coordinate (free disposal). Given a vector of prices 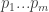 and a budget
and a budget  that consumer’s demand will be the bundle
that consumer’s demand will be the bundle ![x \in [0,1]^m](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B0%2C1%5D%5Em&bg=ffffff&fg=333333&s=0&c=20201002) that maximizes
that maximizes 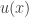 subject to
subject to 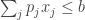 . Looking at this in the old way, the optimization problem of calculating the demand is hard: without any further structure on
. Looking at this in the old way, the optimization problem of calculating the demand is hard: without any further structure on  , an exponential number of queries will be needed. However, they suggest the following way to look at it: our input should be a set of responses that we have seen from the user. Each response is a triplet:
, an exponential number of queries will be needed. However, they suggest the following way to look at it: our input should be a set of responses that we have seen from the user. Each response is a triplet: 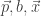 , where
, where 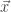 is the bundle demanded by our player when presented with prices
is the bundle demanded by our player when presented with prices 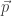 and budget
and budget 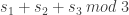 .) They also isolate the problem: when attempting to move from the dual LP to the primal solution, the precision needs to go up, requiring an increase in the bounding Ellipsoid. Finally, they show that the algorithm still finds an approximate correlated equilibrium (in time that is polynomial also in
.) They also isolate the problem: when attempting to move from the dual LP to the primal solution, the precision needs to go up, requiring an increase in the bounding Ellipsoid. Finally, they show that the algorithm still finds an approximate correlated equilibrium (in time that is polynomial also in 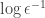 ). The question of whether one can find an exact correlated equilibrium of succinctly represented games in polynomial time remains open.
). The question of whether one can find an exact correlated equilibrium of succinctly represented games in polynomial time remains open.

