Social Choice Theory is a pretty mature field that deals with the question of how to combine the preferences of different individuals into a single preference or a single choice. This field may serve as a conceptual foundation in many areas: political science (how to organize elections), law (how to set commercial laws), economics (how to allocate goods), and computer science (networking protocols, interaction between software agents). Unsurprisingly, there are interesting computational aspects to this field, and indeed a workshop series on computational social choice already exists. The starting point of this field is Arrow‘s theorem that shows the there are unexpected inherent difficulties in performing this preference aggregation. There have been many different proofs of Arrow’s impossibility theorem, all of them combinatorial. In this post I’ll explain a basic observation of Gil Kalai that allows quantifying the level of impossibility using analytical tools (Fourier transform) on Boolean functions commonly used in theoretical computer science. At first Gil’s introduction of these tools in this context seemed artificial to me, but in this post I hope to show you that it is the natural thing to do.
Arrow’s Theorem
Here is our setting and notation:
- There is a finite set of participants numbered
 .
.
- There is a set of three alternatives over which the participants have preferences:
 . (Arrow’s theorem, as well as everything here actually applies also to any set
. (Arrow’s theorem, as well as everything here actually applies also to any set  .)
.)
- We denote by
 the set of preferences over
the set of preferences over  , i.e. is the set of full orders on the elements of .
, i.e. is the set of full orders on the elements of .
The point of view here is that each participant 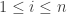 has his own preference
has his own preference  , and we are concerned with functions that reach a common conclusion as a function of the
, and we are concerned with functions that reach a common conclusion as a function of the  ‘s. In principle, the common conclusion may be a joint preference, or a single alternative; Arrow’s theorem concerns the former, i.e. it deals with functions
‘s. In principle, the common conclusion may be a joint preference, or a single alternative; Arrow’s theorem concerns the former, i.e. it deals with functions  called social welfare functions. Arrow’s theorem points out in a precise and very general way that there are no “natural non-trivial” social welfare functions when . (This is in contrast to the case
called social welfare functions. Arrow’s theorem points out in a precise and very general way that there are no “natural non-trivial” social welfare functions when . (This is in contrast to the case  , where taking the majority of all preferences is natural and non-trivial.) Formal definitions will follow.
, where taking the majority of all preferences is natural and non-trivial.) Formal definitions will follow.
A preference  really specifies for each two alternatives
really specifies for each two alternatives 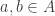 which of them is preferred over the other, and we denote by
which of them is preferred over the other, and we denote by  the bit specifying whether
the bit specifying whether  prefers
prefers  to
to  . We view each as composed of three bits
. We view each as composed of three bits  (where it is implied that
(where it is implied that  ,
,  , and
, and  . Note that under this representation only 6 of the possible 8 three-bit sequences correspond to elements of , where the bad combinations are 000 and 111.
. Note that under this representation only 6 of the possible 8 three-bit sequences correspond to elements of , where the bad combinations are 000 and 111.
The formal meaning of natural is the following:
Definition: A social welfare function  satisfies the IIA (independence of irrelevant alternatives) property if for any two alternatives the aggregate preference between and depends only on the preferences of the participants between and (and not on any preferences with another alternative
satisfies the IIA (independence of irrelevant alternatives) property if for any two alternatives the aggregate preference between and depends only on the preferences of the participants between and (and not on any preferences with another alternative  ). In the notation introduced above it means that
). In the notation introduced above it means that 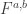 is in fact just a function of the
is in fact just a function of the  bits
bits  (rather than of all the bits in the ‘s).
(rather than of all the bits in the ‘s).
One may have varying opinions of whether this is indeed a natural requirement, but the lack of it does turn out to imply what may be viewed as inconsistencies. For example, when we use the aggregate preference to choose a single alternative (hence obtaining a social choice function), then lack of IIA is directly tied to the the possibility of strategic manipulation of the derived social choice function.
We can take the following definition of non-trivial:
Definition: A social welfare function is a dictatorship if for some  , is the identity function on or the exact opposite order (in our coding, the bitwise negation of ).
, is the identity function on or the exact opposite order (in our coding, the bitwise negation of ).
It is easy to see that any dictatorship satisfies IIA. Arrow’s theorem states that, with another minor assumption, these are the only functions that do so. Kalai’s quantitative proof requires an assumption that is more restrictive than that required by Arrow’s original statement. Recently Elchanan Mossel published a paper without this additional assumption, but we’ll continue with Kalai’s elementary variant.
Definition: A social welfare function is neutral if it is invariant under changing the names of alternatives.
This basically means that as a voting method it does not discriminate between candidates.
Arrow’s Theorem (for neutral functions): Every neutral social welfare function that satisfies IIA is a dictatorship.
Quantification for Arrow’s Theorem
In CS, we are often quite happy with approximation: we know that sometimes things can’t be perfect, but can still be pretty good. Thus if IIA is “perfect”, then the following quantitative version comes up naturally: can there be a function that is “almost” an IIA social welfare function and yet not even close to a dictatorship? Let us define closeness first:
Definition: Two social welfare functions 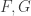 are
are  -close if
-close if ![Pr[F(x_1...x_n) \ne G(x_1 ... x_n)] \le \epsilon](https://s0.wp.com/latex.php?latex=Pr%5BF%28x_1...x_n%29+%5Cne+G%28x_1+...+x_n%29%5D+%5Cle+%5Cepsilon&bg=ffffff&fg=333333&s=0&c=20201002) . The probability is over independent uniformly random choices of .
. The probability is over independent uniformly random choices of .
The choice of the uniform probability distribution over  (strangely termed the impartial culture hypothesis) can not really be justified as a model of the empirical distribution in reasonable settings, but is certainly natural for proving impossibility results which then extend to other reasonably flat distributions. Once we have a notion of closeness of functions, being -almost a dictatorship is well defined by being -close to some dictatorship function. But what is being “almost an IIA social choice function”? The problem is that the IIA condition involves a relation between different values of . This is similar to situation in the field of property testing, and one natural approach is to follow the approach of property testing and quantify how often the desired property is violated:
(strangely termed the impartial culture hypothesis) can not really be justified as a model of the empirical distribution in reasonable settings, but is certainly natural for proving impossibility results which then extend to other reasonably flat distributions. Once we have a notion of closeness of functions, being -almost a dictatorship is well defined by being -close to some dictatorship function. But what is being “almost an IIA social choice function”? The problem is that the IIA condition involves a relation between different values of . This is similar to situation in the field of property testing, and one natural approach is to follow the approach of property testing and quantify how often the desired property is violated:
Definition A: A function  is an -almost IIA social welfare function if for all we have that
is an -almost IIA social welfare function if for all we have that ![Pr[F^{a,b}(x_1...x_n) \ne F^{a,b}(y_1...y_n) | \forall i:x^{a,b}_i=y^{a,b}_i] \le \epsilon](https://s0.wp.com/latex.php?latex=Pr%5BF%5E%7Ba%2Cb%7D%28x_1...x_n%29+%5Cne+F%5E%7Ba%2Cb%7D%28y_1...y_n%29+%7C+%5Cforall+i%3Ax%5E%7Ba%2Cb%7D_i%3Dy%5E%7Ba%2Cb%7D_i%5D+%5Cle+%5Cepsilon&bg=ffffff&fg=333333&s=0&c=20201002) . I.e. for a random input, a random change of the non
. I.e. for a random input, a random change of the non  -bits is unlikely to change the value of .
-bits is unlikely to change the value of .
A second approach is simpler although surprising at first, and instead of relaxing the IIA requirement, relaxes the social welfare one. I.e. we can allow to have in its range all possible 8 values in  rather than just the 6 in . We call the bad values, 000 and 111, irrational outcomes, as they do not correspond to a consistent preference on .
rather than just the 6 in . We call the bad values, 000 and 111, irrational outcomes, as they do not correspond to a consistent preference on .
Definition B: A function  is an -almost IIA social welfare function if it is IIA and there exists a social choice function
is an -almost IIA social welfare function if it is IIA and there exists a social choice function  such that and
such that and  are -close.
are -close.
Note that we implicitly extended the definitions of closeness and of being IIA from functions having a range of to those also with a range of 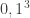 .
.
We can now state Kalai’s quantitative version of Arrow’s theorem:
Theorem (Kalai): For every  there exists a
there exists a 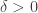 such that every neutral function that is
such that every neutral function that is  -almost an IIA social choice function is -almost a dictatorship.
-almost an IIA social choice function is -almost a dictatorship.
Following Kalai, we will prove the theorem for definition B of “almost”, but the same theorem for definition A directly follows: take a function that is an -almost IIA social welfare according to definition A, and define a new function 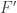 by letting
by letting  to be the majority value of
to be the majority value of  where the
where the  ‘s agree with the ‘s on their -bit and range over all possibilities on the other bits. By definition is IIA, and it is not difficult to see that since satisfied definition A, then the majority vote in the definition is almost always overwhelming and thus is
‘s agree with the ‘s on their -bit and range over all possibilities on the other bits. By definition is IIA, and it is not difficult to see that since satisfied definition A, then the majority vote in the definition is almost always overwhelming and thus is  -close to (where
-close to (where  ). Since we defined each bit of separately, its range may contain irrational outcomes, but since it is close to , at most of these, and thus it satisfies definition B.
). Since we defined each bit of separately, its range may contain irrational outcomes, but since it is close to , at most of these, and thus it satisfies definition B.
The main ingredient of the proof will be an analysis of the correlation between two bits from the output of .
Main Lemma (social choice version): For every there exists a such that if a neutral is not -almost a dictatorship then ![Pr[F^{a,b}(x_1...x_n)=1\:and\:F^{b,c}(x_1...x_n)=0] \le 1/3-\delta](https://s0.wp.com/latex.php?latex=Pr%5BF%5E%7Ba%2Cb%7D%28x_1...x_n%29%3D1%5C%3Aand%5C%3AF%5E%7Bb%2Cc%7D%28x_1...x_n%29%3D0%5D+%5Cle+1%2F3-%5Cdelta&bg=ffffff&fg=333333&s=0&c=20201002) .
.
Before we proceed, let us look at the significance of the  : If the values of and
: If the values of and  were completely independent, then the joint probability would be exactly
were completely independent, then the joint probability would be exactly 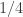 (since each of the two bits is unbiased due to the neutrality of ). For a “random” the value obtained would be almost . In contrast, if is a dictatorship then the joint probability would be exactly
(since each of the two bits is unbiased due to the neutrality of ). For a “random” the value obtained would be almost . In contrast, if is a dictatorship then the joint probability would be exactly 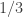 since
since ![Pr[x_i^{a,b}=1\:and\:x_i^{b,c}=0]=1/3](https://s0.wp.com/latex.php?latex=Pr%5Bx_i%5E%7Ba%2Cb%7D%3D1%5C%3Aand%5C%3Ax_i%5E%7Bb%2Cc%7D%3D0%5D%3D1%2F3&bg=ffffff&fg=333333&s=0&c=20201002) as is uniform in . The point here is that if has non-negligible difference from being a dictatorship then the probability is non-negligibly smaller than .
as is uniform in . The point here is that if has non-negligible difference from being a dictatorship then the probability is non-negligibly smaller than .
The theorem is directly implied from this lemma as the event 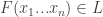 is the disjoint union of the three events
is the disjoint union of the three events  ,
, 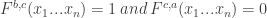 , and
, and  , whose total probability, if is not -almost a dictatorship, is bounded by the lemma by
, whose total probability, if is not -almost a dictatorship, is bounded by the lemma by  and thus the probability of an irrational outcome is at least
and thus the probability of an irrational outcome is at least 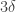 .
.
So let us inspect this lemma. We have two Boolean functions and each operating on -bit strings. Since is neutral, these are actually the same Boolean function, so  . What we are asking is for the probability that
. What we are asking is for the probability that  where
where  and
and  are each an -bit strings:
are each an -bit strings: 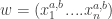 and
and  . The main issue how and are distributed. Well, is uniformly distributed over
. The main issue how and are distributed. Well, is uniformly distributed over  and so is . They are not independent though:
and so is . They are not independent though: ![Pr[w_i=z_i]=1/3](https://s0.wp.com/latex.php?latex=Pr%5Bw_i%3Dz_i%5D%3D1%2F3&bg=ffffff&fg=333333&s=0&c=20201002) . We say that the distributions on and are (anti-1/3-)correlated.
. We say that the distributions on and are (anti-1/3-)correlated.
So our main lemma is equivalent to the following version of the lemma which now talks solely of Boolean functions:
Main Lemma (Boolean version): For every there exists a such that if an odd Boolean function  is not -almost a dictatorship then
is not -almost a dictatorship then ![Pr[f(z)=1\:and\:f(w)=0] \le 1/3-\delta](https://s0.wp.com/latex.php?latex=Pr%5Bf%28z%29%3D1%5C%3Aand%5C%3Af%28w%29%3D0%5D+%5Cle+1%2F3-%5Cdelta&bg=ffffff&fg=333333&s=0&c=20201002) , where is chosen uniformly at random in and chosen so that
, where is chosen uniformly at random in and chosen so that ![Pr[w_i = z_i]=1/3](https://s0.wp.com/latex.php?latex=Pr%5Bw_i+%3D+z_i%5D%3D1%2F3&bg=ffffff&fg=333333&s=0&c=20201002) and
and ![Pr[w_i=-z_i]=2/3](https://s0.wp.com/latex.php?latex=Pr%5Bw_i%3D-z_i%5D%3D2%2F3&bg=ffffff&fg=333333&s=0&c=20201002) .
.
An odd Boolean function just means that  which is follows from the neutrality of by switching the roles of and . (We really only need that
which is follows from the neutrality of by switching the roles of and . (We really only need that  is “balanced”, i.e. takes value 1 on exactly 1/2 of the inputs, but lets keep the more specific requirement for compatibility with the previous version of this lemma.)
is “balanced”, i.e. takes value 1 on exactly 1/2 of the inputs, but lets keep the more specific requirement for compatibility with the previous version of this lemma.)
Fourier Transform on the Boolean Cube
At this point using the Fourier transform is quite natural. While I do not wish to give a full introduction to the Fourier transform on the Boolean cube here, I do want to give the basic flavor in one paragraph, convincing those who haven’t looked at it yet to do so. 1st year algebra and an afternoon’s work should suffice to fill in all the holes.
The basic idea is to view Boolean functions  as special cases of the real-valued functions on the Boolean cube:
as special cases of the real-valued functions on the Boolean cube:  . This is a real vector space of dimension
. This is a real vector space of dimension  , and has a natural inner product
, and has a natural inner product  The
The 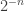 factor is just for convenience and allows viewing the inner product as the expectation over a random choice of :
factor is just for convenience and allows viewing the inner product as the expectation over a random choice of : ![<f,g> = E[f(x)g(x)]](https://s0.wp.com/latex.php?latex=%3Cf%2Cg%3E+%3D+E%5Bf%28x%29g%28x%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) . As usual the choice of a “nice” basis is helpful and our choice is the “characters”: functions of the form
. As usual the choice of a “nice” basis is helpful and our choice is the “characters”: functions of the form  , where
, where  is some subset of the bits.
is some subset of the bits.  takes values -1 and 1 according to the parity of the bits of in . There are such characters and they turn out to be an orthonormal basis. The Fourier coefficients of , denoted
takes values -1 and 1 according to the parity of the bits of in . There are such characters and they turn out to be an orthonormal basis. The Fourier coefficients of , denoted 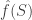 , are simply the coefficients under this basis
, are simply the coefficients under this basis  , where we have that
, where we have that  .
.
One reason why this vector space is appropriate here is that the correlation operation we needed between and in the lemma above, is easily expressible as a linear transformation  on this space defined by
on this space defined by ![(Tf)(x)=E[f(y)]](https://s0.wp.com/latex.php?latex=%28Tf%29%28x%29%3DE%5Bf%28y%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) where
where  is chosen at random with
is chosen at random with ![Pr[y_i = x_i]=1/3](https://s0.wp.com/latex.php?latex=Pr%5By_i+%3D+x_i%5D%3D1%2F3&bg=ffffff&fg=333333&s=0&c=20201002) and
and ![Pr[y_i=-x_i]=2/3](https://s0.wp.com/latex.php?latex=Pr%5By_i%3D-x_i%5D%3D2%2F3&bg=ffffff&fg=333333&s=0&c=20201002) . Using this it is possible to elementarily evaluate the probability in the lemma as
. Using this it is possible to elementarily evaluate the probability in the lemma as 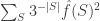 , where the sum ranges over all subsets of the bits. To get a feel of what this means we need to compare it with the following property of the Fourier transform of a balanced Boolean function:
, where the sum ranges over all subsets of the bits. To get a feel of what this means we need to compare it with the following property of the Fourier transform of a balanced Boolean function: 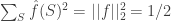 . The difference between this sum and our sum is the factor of
. The difference between this sum and our sum is the factor of  for each term. The “first” element is this sum is easily evaluated for a balanced function:
for each term. The “first” element is this sum is easily evaluated for a balanced function: ![\hat{f}(\emptyset)^2 =(E[f])^2 = 1/4](https://s0.wp.com/latex.php?latex=%5Chat%7Bf%7D%28%5Cemptyset%29%5E2+%3D%28E%5Bf%5D%29%5E2+%3D+1%2F4&bg=ffffff&fg=333333&s=0&c=20201002) , so in order to prove the main lemma it suffices to show that
, so in order to prove the main lemma it suffices to show that  . This is so as long as a non-negligible part of
. This is so as long as a non-negligible part of  is multiplied by a factor strictly smaller than
is multiplied by a factor strictly smaller than  , i.e. is on sets
, i.e. is on sets  . Thus the main lemma boils down to showing that if
. Thus the main lemma boils down to showing that if 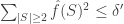 then is -almost a dictatorship. This is not elementary but is proved by E. Friedgut, G. Kalai, and A. Naor and completes our journey from Arrow to Fourier.
then is -almost a dictatorship. This is not elementary but is proved by E. Friedgut, G. Kalai, and A. Naor and completes our journey from Arrow to Fourier.
More results
There seems much promise in using these analytical tools for addressing quantitative questions in social choice theory. I’d like to mention two results of this form. The first is the celebrated MOO paper (by E. Mossel, R. O’Donnell and K. Oleszkiewicz) that proves, among other things, that among functions that do not give any player unbounded influence, the closest to being an IIA social welfare function is the majority function. The second, is a paper of mine with E. Friedgut and G. Kalai that obtains a quantitative version of the Gibbard–Satterthwaite theorem showing that every voting method that is far from being a dictatorship can be strategically manipulated. Our version shows that this can be done on a non-negligible fraction of preferences, but is limited to neutral voting methods between 3 candidates.

Thanks for the long entry.
I found O Donnel’s survey paper specially useful to get an overview of Fourier analysis applications in social choice theory:
Click to access analysis-survey.pdf
It also covers applications of Boolean function analysis to prove inapproximability of important problems.
I like the idea of including irrational preferences (as well as simplisity) in Definition B of e-almost IIA sw functions. But before allowing those two bad preferences 000 and 111, I would extend the range to include the preferences that contain indifferences. To me, ruling out indifferences on the domain is okay, but ruling them out on the range can be too restrictive.
Usually taking this (minor) point into consideration just complicates the proof, though. Hopefully the same is true for this approach based on Boolean functions (simple games).
—From a social choice guy that works on the boundary of Algorithmic Game Theory and something else.
The link to Elchanan Mossel’s paper is broken.
Haris: thanks for the link — I added it to the post.
Reiju: I don’t know whether handling indifferences is just a technical nuisance using the Fourier approach or whether it opens up new issues — there has been only little work on this so far.
Preyas: Thanks. I fixed the link.
This is a lovely post. I could not have written it so well, but probably I can write about it not as good with some more angles. I will try it some time.
thanks. please do!
Very nice post. However, it’s not quite true that all the proofs of Arrow’s theorem are combinatorial. You might be interested in the paper “Unifying Impossibility Theorems: A Topological Approach” by Baryshnikov. This proof could only be called combinatorial insofar as it is relies on the topology of simplicial complexes which are combinatorial objects.
Thanks for the reference. Is there an online link? I couldn’t find one.
http://dx.doi.org/10.1006/aama.1993.1020 if you have a subscription to ScienceDirect.
[…] own called “Algorithmic game theory” of with interesting posts on the econ-CS interface. One post is about Fourier theoretic proof of Arrow’s theorem and the recent paper by Noam, Ehud Friedgut […]
There is an electronic version to another paper by Yuliy Baryshnikov: http://www.springerlink.com/content/l6byjxktnm1n3358/fulltext.pdf
Topological social choice is a fairly developed area and it is related to the issue of “averaging” in mathematics. A recent paper by Shmuel Weinberger with links to earlier papers is here:
Click to access dp282.pdf
Thanks for the links, Gil, Boris, and Noah.
[…] blogs: Michael Nielsen’s, the Geomblog, Black belt Bayesian, Secret blogging seminar, and Algorithmic game theory, to name a few. Possibly related posts: (automatically generated)Reading Notes: Chapter 4: Group […]
[…] New paper: average-case manipulation of elections The classic Gibbard-Satterthwaite theorem states that every nontrivial voting method can be manipulated. In the late 1980’s an approach to circumvent this impossibility was suggested by Bartholdi, Tovey, and Trick: maybe a voting method can be found where the manipulation is computationally hard — and thus effective manipulation would be practically impossible? Indeed voting methods whose manipulation problem was NP-complete were found by them as well as later works. However, this result is not really satisfying: the NP-completeness only ensures that the manipulation cannot be solved in the worst case; it is quite possible that for most instances manipulation is easy, and thus the voting method can still be effectively manipulated. What would be desired is a voting method where manipulation would be computationally hard everywhere, except for a negligible fraction of inputs. In the last few years several researchers have indeed attempted “amplifying” the NP-hardness of manipulation in a way that may get closer to this goal. The new paper of Marcus Isaksson, Guy Kindler, and Elchanan Mossel titled The Geometry of Manipulation – a Quantitative Proof of the Gibbard-Satterthwaite Theorem shatters these hopes. Solving the main open problem in a paper by Ehud Freidgut, Gil Kalai, and myself, they show that every nontrivial neutral voting method can be manipulated on a non-negligible fraction of inputs. Moreover, a random flip of the order of 4 (four) alternatives will be such a manipulation, again with non-negligible probability. This provides a quantitative version of the Gibbard-Satterthwaite theorem, just like Gil Kalai previously obtained a quantitative version of Arrow’s theorem. […]
[…] starts with the classic KKL work on influences and reaches some of his modern results on approximation in computational social choice. Gil also writes on ICS in his […]
I am planning on going to beauty school when I’m older, and mainly going to school for hairstyling stuff. So what are the top 3 beauty schools in Texas?.
[…] to a Fourier-theoretic proof of Arrow theorem (in the balanced case). You can find it discussed in this blog post by Noam Nisan. Lecture 10 mentioned a few further application of the Fourier method related to […]
[…] Most proofs of Arrow’s theorem are combinatorial in nature. In 2002 Gil Kalai gave a clever proof based on Boolean Fourier analysis. Noam Nisan goes over this proof in a 2009 blog post. […]
[…] who does not know much about social choice theory and who likes voting systems) that it implies a quantitative version of Arrow’s […]